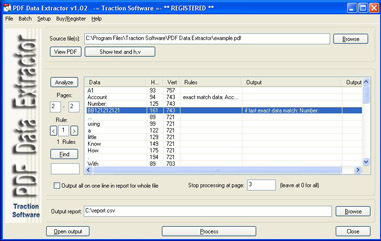
PDF Data Extractor puede extraer cierta información de texto dentro del PDF, este es un producto ideal si usted tenía por ejemplo una declaración en PDF que necesita para extraer datos como número de cuenta, nombre, dirección y la salida de esta información en un archivo CSV de Excel. Utiliza la coincidencia horizontal y vertical de la posición del texto y, para una coincidencia más avanzada, tiene un sistema de reglas para la concordancia condicional, p. Solo tome el partido cuando el número de cuenta: el texto esté en la misma página. Los campos diferentes se pueden también combinar en uno, así que el primer nombre y el apellido se pueden salir como un campo en el archivo de CSV, convertir el formato pdf de la hoja de balance a los archivos del csv, muchas opciones están disponibles: Extracción de datos, , Campo de número de página, campo de nombre de archivo, lista de lotes de archivos a procesar.
También puede ahora renombrar o copiar archivos a una nueva ubicación basada en datos extraídos.
NOTA: Este software es autónomo, es decir, no requiere Adobe Acrobat para ejecutarse
Evaluación Las restricciones son: - pantallas nag, texto de prueba y 5 archivos en modo por lotes.
¿Necesita un extractor de datos personalizado para crear sus archivos PDF específicos?
Hemos hecho varias versiones a medida de este producto para informes más complicados como informes de la policía, facturas, etc a la salida del archivo csv, con un archivo más simple en / interfaz de archivo de salida - póngase en contacto con nosotros para una cotización razonable. Es nuevo en esta versión:
- Versión 1.05:
Qué es nuevo en la versión 1.04:
Versión 1.04:
1. la fila agregada ajusta para los tamaños flotantes de la fila, fósforo en el texto de h.
2. cambio de volcado de texto para incluir todas las fuentes, fuentes incrustadas y subconjunto.
Limitaciones
>
Comentarios que no se encuentran