El software libre OCR para extraer texto de archivos de imagen y artículos PDF. Una interfaz gráfica de usuario (GUI) para el motor de OCR Tesseract.
La aplicación es fácil de instalar y, más importante aún, de uso gratuito, de código abierto y 100% libre de adware y spyware.
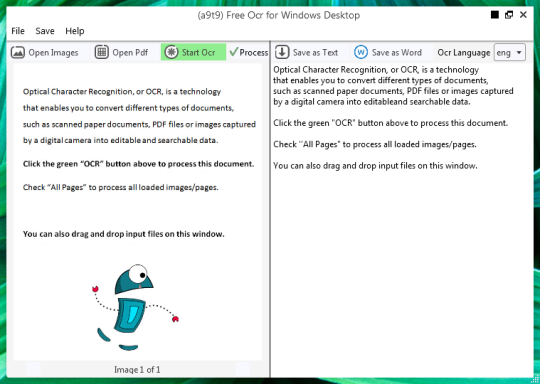
Puede abrir un archivo de imagen o PDF. El contenido del archivo fuente se mostrará en la ventana izquierda. Si el documento como más de una página, o si abrió documentos de varias páginas, utilice las flechas en la parte inferior para cambiar entre ellos,
Comienzas el OCR haciendo clic en el botón verde OCR, y verá el resultado en la segunda ventana de la derecha. Texto de salida se pueden guardar como un archivo de texto o documento de Word.
Desafortunadamente, la calidad de conversión no es tan grande. Detrás de la escena que utiliza el motor de OCR de código abierto Tesseract. La calidad varía de una lengua a otra -. Así que adelante y probar si es suficiente para sus necesidades
Para los desarrolladores de software y los geeks: El OCR libre para la herramienta de escritorio de Windows es básicamente una interfaz de usuario interfaz gráfica de usuario (GUI) para el motor de OCR Tesseract. El código fuente completo está disponible (licencia GPL).
El motor de OCR del software es compatible con el siguiente texto OCR: Inglés, francés, italiano, alemán, español, portugués y holandés brasileño. Desde la versión 3 se puede reconocer árabe, búlgaro, catalán, chino (simplificado y tradicional), croata, checo, danés, holandés, Inglés, Alemán (estándar y la escritura Fraktur), griego, finlandés, francés, hebreo, hindi, húngaro, indonesio, italiano, japonés, coreano, letón, lituano, noruego, polaco, portugués, rumano, ruso, serbio, eslovaco (estándar y la escritura Fraktur), esloveno, español, sueco, tagalo, tamil, tailandés, turco, ucraniano y vietnamita.
Comentarios que no se encuentran