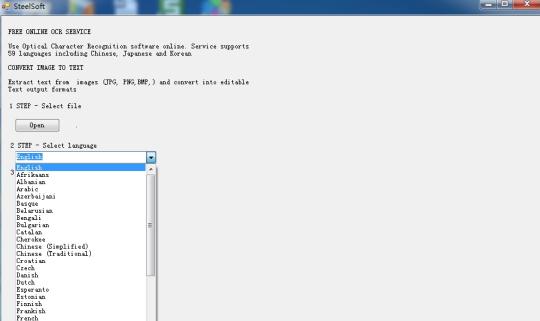
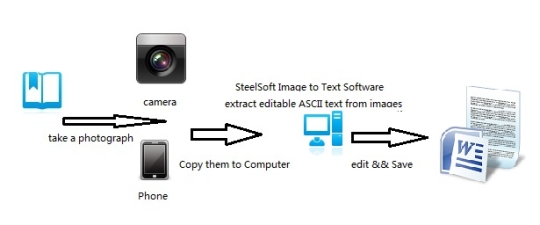
Reconocer texto de imágenes utilizando el motor de OCR Tesseract basado en la tecnología de nube.
Utilice el software de reconocimiento óptico de caracteres en línea. Servicio soporta 59 idiomas, incluyendo chino, japonés y coreano. Extraer texto de imágenes (JPG, PNG, BMP, TIF) y convertir a formatos de salida de texto editables.
Se basa en la tecnología de nube, y muy famoso motor de OCR (OCR Tesseract Motor), por lo que sólo hay cientos de KB de tamaño, pero puede extraer el texto en 59 idiomas, desde las imágenes.
Es compatible con más idiomas: búlgaro, catalán, checo, danés, holandés, inglés, finlandés, francés, alemán, griego, húngaro, indonesio, italiano, letón, lituano, noruego, polaco, portugués, rumano, ruso, serbio, eslovaco, esloveno , español, sueco, tagalo, turco, ucraniano, vietnamita, etc.
¿Cuál es nuevo en esta versión:..
La versión 5.0 incluye mejoras de la UE
Comentarios que no se encuentran