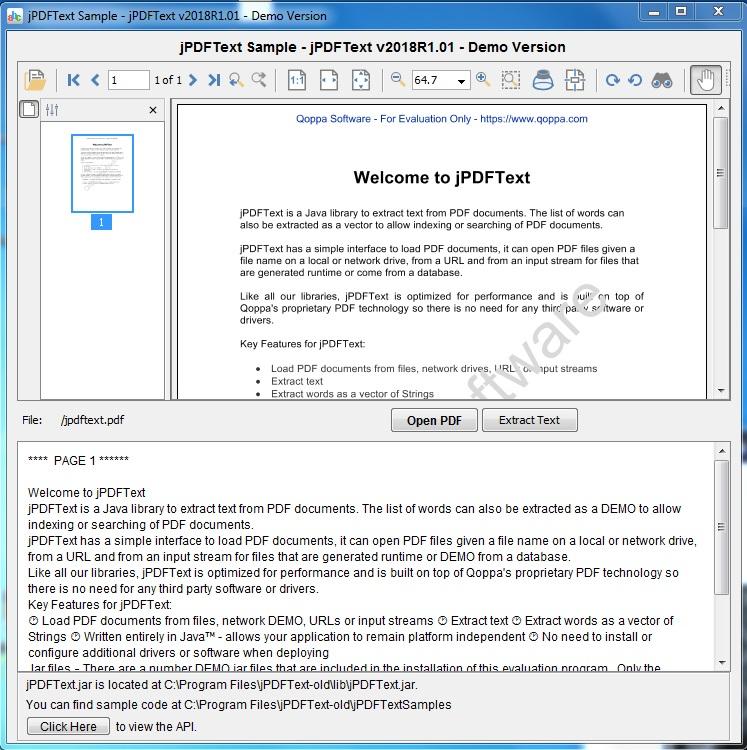
jPDFText es una biblioteca de Java para extraer texto de documentos PDF. Con jPDFText, los documentos PDF se pueden procesar para extraer el contenido textual para archivar, almacenar, buscar o indexar. jPDFText se basa en la tecnología de PDF patentada de Qoppas para que no tenga que instalar ningún software o controlador de terceros. Dado que está escrito en Java, permite que su aplicación permanezca independiente de la plataforma y se ejecute en Windows, Linux, Unix (Solaris, HP UX, IBM AIX), Mac OS X y cualquier otra plataforma que admita el entorno de ejecución de Java.
Principales características:
Cargue documentos PDF desde archivos, unidades de red, URL o flujos de entrada.
Extraer texto en el orden de lectura lógico.
Extrae palabras como un vector de cuerdas.
Funciona en Windows, Linux, Unix y Mac OS X (100% Java).
No es necesario instalar o configurar controladores o software adicionales durante la implementación.
Probado en JDK 1.4.2 y superior.

Comentarios que no se encuentran